
Due to a convergence of mostly-unfortunate factors, I have been embroiled in trying to sort out our university’s submission to the national student financial aid system (NSFAS)…this being driven by
- an 8-week long staff strike that saw me with zero-out-of-33 staff available before the (first of…) submission deadline for student “registration template” data.
(And the tales-of-staff-strike deserves a whole nother series of blog posts for my memoirs…) - A scramble to implement “free education” due to a last-gasp-populist presidential edict from ex-president Zuma…this suddenly meant that a whole whack of students now qualified for financial aid who previously didn’t and therefore hadn’t applied but now came to the university and needed to be registered (and we will sort the rest out…)
Part 1: The data…
The first part was generating “registration template” data for all students that we had registered on the understanding that they would qualify for NSFAS funding. This ends up being a messy mix of…current registration status, counts of courses being repeated, contact details and a breakdown of registration / tuition / accomodation costs plus applicable allowances.
I wrote some python scripts that mixed various CSV and XLS inputs and Oracle DB queries…and could regenerate these templates for all students in about 10 mins by running a single script…which then merged the 8 CSV outputs corresponding the the 8 categories of funded students into an XLSX file with 8 sheets.
(Yay for openpyxl. But…one thing I find about python…you have to use more awkward libraries (xlrd / xlwt) for the older XLS spreadsheet format…and the code is very different (and reading and writing a sheet involves some quite messy data transformations as the readers and writers have different data models. It’s easier to use than Apache-POI / HSSF in java, but the POI stuff is consistent over different formats, etc…)
(NB also…for quick-and-dirty stuff, if I’m not going to write XLS(X) format, I just use in2csv piped to stdin…and create a csv.reader(sys.stdin))
Part 2: The recon
Pretty soon…there was chaos…with a bazillion spreadsheets / CSVs and trying to upload these on the MyNSFAS portal to submit data. Confusing error messages — ID Number not found…which as far as can figure out…seems to be a wrapper around “Some exception was thrown”, as we discovered ID Number not found often-as-not meant “there are non-numeric / blank chars in the cellphone number”.
We had ~14200 students we had “coded” (as NSFAS eligible) and registered. The FundedReport CSV that we could download from the MyNSFAS portal has 12556 students…
…But
soren@dut-dwg-test:~/ITSqueries/NSFAS/recon$ ./diffsum.sh allreg.ids all-funded.ids 14621 only in file allreg.ids 9370 lines in common 3186 only in file all-funded.ids
only 9370 of these students are registered with us. There’s a big, scary gap…
soren@dut-dwg-test:~/ITSqueries/NSFAS/recon$ ./diffsum.sh all-funded.ids DUT-all-coded.ids 4090 only in file all-funded.ids 8466 lines in common 6085 only in file DUT-all-coded.ids
…of 6085 students who we have registered but don’t appear on the funded report.
Part 2.5: The web service
MyNSFAS had a query form where I could look up the funding status for a student (ID number). I did a few queries for some of the “missing” students, and noted that I got different results — some students came back as “ID not found”, some came back with Funder / Funded status information.
So I knew that the information that I got from the FundedReport was incomplete. It would be nice if I could get the Funded status information for all our students.
Chrome dev tools are your friend…
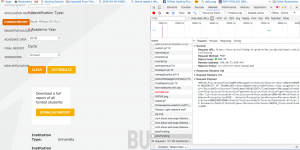
we can see the XML request and the target URL of the service. This is also pretty easy to see in the javascript on the page
var pfpdataRequest = "<NSFAS_ProvisionalFundingRQ>"+
"<MessageInformation>"+
"<Source>"+
"<SourceName>"+$("#InstitutionName").val()+"</SourceName>"+
"<SourceURI>http://www.oxygenxml.com/</SourceURI>"+
"</Source>"+
"<TimeStamp>1481021367</TimeStamp>"+
"</MessageInformation>"+
"<Institution>"+
"<InstitutionType>"+$("#InstitutionType").val()+"</InstitutionType>"+
"<InstitutionId> "+ $("#InstitutionID").val()+"</InstitutionId>"+
"</Institution>"+
"<EffectiveDate>2006-05-04</EffectiveDate>"+
"<ProcessCycle>"+$('select[name=pfProcessCycle]').val()+"</ProcessCycle>"+
"<Persons>"+
"<Person>"+
"<Identification>"+$('input[name=pfIdentification]').val()+"</Identification>"+
"<IdentificationType>"+$('input[name=pfIdentificationType]').val()+"</IdentificationType>"+
"</Person>"+
"</Persons>"+
"</NSFAS_ProvisionalFundingRQ>";
var wsURL = "https://msvc-prvsnlfndng-v1-prod-nsfas.eu-gb.mybluemix.net/provFunding"
var request = new XMLHttpRequest();
request.open ("POST",wsURL, false);
request.setRequestHeader("token",window.btoa($("input[name=token]").val()));
request.send(pfpdataRequest);
so this is pretty straightforward. I can knock this up in python + requests… (and…why I am not brave enough todo this in NodeJS, since I started with “borrowed” JS code. Next time…)
Also, the fact that the <Person/> node is wrapped in a <Persons/> node suggests we can send a list of IDs…which I test, and it works.
def provFundedXmlReq(id_list,rsp_parser):
personIdTmp = """<Person>
<Identification>%s</Identification>
<IdentificationType>%s</IdentificationType>
</Person>
"""
xmlReqTmp = """<NSFAS_ProvisionalFundingRQ>
<MessageInformation>
<Source>
<SourceName>%s</SourceName>
<SourceURI>http://www.oxygenxml.com/</SourceURI>
</Source>
<TimeStamp>1481021367</TimeStamp>
</MessageInformation>
<Institution>
<InstitutionType>%s</InstitutionType>
<InstitutionId>%s</InstitutionId>
</Institution>
<EffectiveDate>2006-05-04</EffectiveDate>
<ProcessCycle>%s</ProcessCycle>
<Persons>
%s
</Persons>
</NSFAS_ProvisionalFundingRQ>"""
#
# build person list
plist = []
for id in id_list:
vals = (id,"South African ID Document")
plist.append(personIdTmp % vals)
plistS = "".join(plist)
# insert into xml request template
vals = ('DURBAN UNIVERSITY OF TECHNOLOGY',
'University',
' 111',
'2018 - Annual',
plistS
)
xmlReq = xmlReqTmp % vals
# print xmlReq
# post to endpoint
headers = {'Content-Type': 'application/xml','token':token} # set what your server accepts
xmlrsp = requests.post(wsURL, data=xmlReq, headers=headers).text
parser_xml = xmlrsp.encode('ascii','ignore')
print parser_xml
To get this to work, I had to cut-n-paste an auth token from the request headers that I got from the chrome dev tools network request inspector.
Then I had an XML response…
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><NSFAS_ProvisionalFundingRS><Success/><ProvisionalFunding><ProvisionallyFunded><Institution><Inst itutionType>University</InstitutionType><InstitutionId>115</InstitutionId></Institution><StudentDetails Race="Other"><PersonName><GivenName>millenium qu een</GivenName><Surname>ramphadi</Surname></PersonName></StudentDetails><Person><Identification>0001011893086</Identification><IdentificationType>South African ID Document</IdentificationType></Person><ApplicationReferenceNumber>OA201709196877872</ApplicationReferenceNumber><ApplicantIndicator>true</App licantIndicator><ReturningStudentIndicator>false</ReturningStudentIndicator><EFC><CurrencyCode>ZAR</CurrencyCode><DecimalPlaces>2</DecimalPlaces><Amount >0.0</Amount></EFC><FundingYear>2018</FundingYear><Cycle>2018 - Annual</Cycle><Funded>true</Funded><Funder>DHET/Grant _92_DUT-Learner-2018</Funder><CAPs ><CAP><CAPType>Annual Registration</CAPType><Amount><CurrencyCode>ZAR</CurrencyCode><DecimalPlaces>2</DecimalPlaces><Amount>0.0</Amount></Amount></CAP>< CAP><CAPType>Annual Tuition</CAPType><Amount><CurrencyCode>ZAR</CurrencyCode><DecimalPlaces>2</DecimalPlaces><Amount>0.0</Amount></Amount></CAP><CAP><CA PType>Annual Accommodation</CAPType><Amount><CurrencyCode>ZAR</CurrencyCode><DecimalPlaces>2</DecimalPlaces><Amount>0.0</Amount></Amount></CAP><CAP><CAP Type>Annual Book</CAPType><Amount><CurrencyCode>ZAR</CurrencyCode><DecimalPlaces>2</DecimalPlaces><Amount>0.0</Amount></Amount></CAP><CAP><CAPType>Annua l Travel</CAPType><Amount><CurrencyCode>ZAR</CurrencyCode><DecimalPlaces>2</DecimalPlaces><Amount>0.0</Amount></Amount></CAP><CAP><CAPType>Annual Meals< /CAPType><Amount><CurrencyCode>ZAR</CurrencyCode><DecimalPlaces>2</DecimalPlaces><Amount>0.0</Amount></Amount></CAP><CAP><CAPType>Qualification Disabili :
…which you can pipe through xmlindent for read/grok-ability.
The rest is…dog work with xml.minidom…and I can get status for all 27000-odd students…I pushed this into MySQL with data from the funded lists, registration & flagging from our student system, etc. This aggregate data allows me to make sense of our applications & where our problem areas are:
mysql> select fundedids,count(*) from ALL_PROVFUND where Annual_tuition is not NULL and dut_all_reg is not NULL group by fundedids; +------------+----------+ | fundedids | count(*) | +------------+----------+ | NULL | 4409 | | funded.ids | 9377 | +------------+----------+ 2 rows in set (0.50 sec)
I find another 4409 students that have NSFAS applications that are not on the FundedReport that we can submit template data for.
mysql> select ch2ids,count(*) from ALL_PROVFUND where Annual_Tuition is NULL and dut_coded is not NULL group by ch2ids ; +---------+----------+ | ch2ids | count(*) | +---------+----------+ | NULL | 1089 | | ch2.ids | 1492 | +---------+----------+ 2 rows in set (0.06 sec)
which uncovers 1089 students that we have admitted, and do not have any NSFAS application info and are not in process in “Channel 2”.
xxx